Multilinguality in Transformers
The following paper: Do Multilingual Neural Machine Translation Models Contain Language Pair Specific Attention Heads? asks a very good question. To answer it, the publishers tried to measure the importance of the self-attention heads in the encoder and the encoder-decoder attention heads of a many-to-one transformer. The NMT model was able to translate French, German, Italian, Spanish, and Korean sentences to English. It uses a variant of the Transformer-Big architecture with a shallower decoder: 16 attention heads, 6 encoder layers, and 3 decoder layers on TED2020 dataset.
Denoting $\left| I \right|,\ \left| J \right|$ as the number of source tokens and/or target tokens depending on whether we looked at the self-attention of encoder or the encoder-decoder cross attentions, The metrics used for importance are three:
- Confidence:
It is the mean of its maximum attention weights.
- Variance:
It’s measured by how much each individual position $i$ is away from the expected position $\mu_{i}$:
- Coverage:
It measures the amount of attention a source token has received.
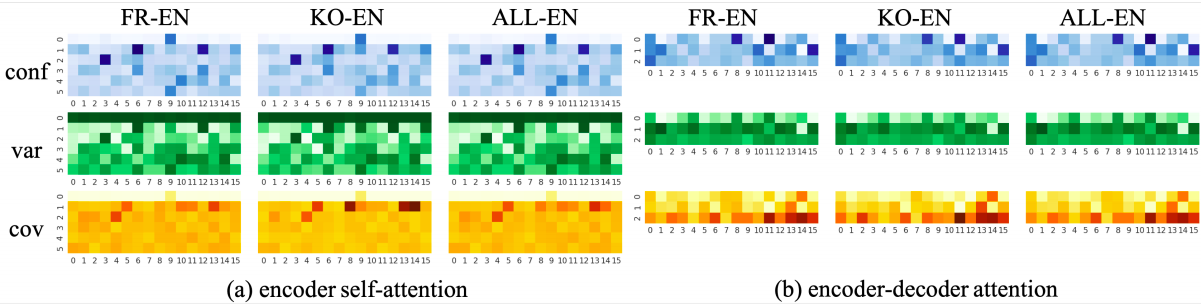
According to the paper, the most important heads are language-independent as you can see in the following figure:
Note:
Even though most important heads are language-independent, in the paper they showed that it is possible to find the rare heads specific to a language pair via the extensive SBS (sequential backward selection) procedure.